Secciones
Software Libre
Distribuciones
Mantente al día
|
Configuración de Subversion + WebSVN en Debian Jessie
Para configurar un servidor de Subversion en Debian Jessie hay un par de cosas a tener en cuenta, principalmente si se quiere hacer funcionar con WebSVN. En primer lugar se instalan los paquetes necesarios:
$ su -
y posteriormente se crea el respositorio, en este caso para almacenar unas webs en un servidor local:
# apt-get update && apt-get install subversion subversion-tools apache2 libapache2-svn
# mkdir -p /d/svn
Los permisos de acceso se pueden definir en la ruta del repositorio /d/svn/webs/conf/svnserve.conf, aunque en este caso lo dejaremos
por defecto.
# svnadmin create /d/svn/webs El fichero /etc/apache2/mods-available/dav_svn.conf se modifica para añadir el fichero para la autenticación en Apache:
<Location /svn>
Para el acceso y la gestión del Subversion, se establecen los permisos que se deseen:
DAV svn SVNParentPath /d/svn AuthType Basic AuthName "Subversion Repository" AuthUserFile /etc/apache2/dav_svn.passwd Require valid-user </Location>
# groupadd subversion
Para probar que se accede correctamente se puede utilizar: # svnlook tree /d/svn/webs/
# addgroup vs2 subversion # chown -R www-data:subversion /d/svn/ # chmod -R 770 /d/svn/ # htpasswd -c /etc/apache2/dav_svn.passwd vs2 # invoke-rc.d apache2 restart Una vez que el repositorio está generado correctamente, se puede comenzar a añadir contenido
$ cd /d/
El contenido se puede visualizar mediante el navegador web con el usuario creado previamente (http://localhost/svn/webs), aunque
queda un poco soso y le daremos color. Para ello instalamos WebSVN:
$ svn co --username vs2 http://localhost/svn/webs (El comando anterior habrá creado el directorio /d/webs, ahora añadimos una carpeta llamada test) $ cd /d/webs/ && mkdir test $ svn add test $ svn commit -m "Carpeta de prueba"
# apt-get install enscript websvn libapache2-mod-php5 cadaver
Editar el fichero de configuración para añadir el coloreado de sintaxis
(En la configuración, seleccionar sólo Apache2 y usar /d/svn/webs como 'SVN Parent Repositories' y como 'SVN repositories')
# vi /etc/websvn/svn_deb_conf.inc
Probar que se accede a los repositorios por línea de comandos: cadaver http://localhost/svn/webs
<?php // please edit /etc/websvn/config.php // or use dpkg-reconfigure websvn $config->parentPath("/d/svn/webs"); $config->addRepository("repos 1", "file:///d/svn/webs"); $config->setEnscriptPath("/usr/bin"); $config->setSedPath("/bin"); $config->useEnscript(); $extEnscript[".java"] = "java"; $extEnscript[".pl"] = "perl"; $extEnscript[".py"] = "python"; $extEnscript[".sql"] = "sql"; $extEnscript[".java"] = "java"; $extEnscript[".html"] = "html"; $extEnscript[".xml"] = "html"; $extEnscript[".thtml"] = "html"; $extEnscript[".tpl"] = "html"; $extEnscript[".sh"] = "bash"; ?> La configuración del Apache se ha visto modificada en algunos puntos en las últimas versiones, en este caso concreto la 2.4.6, lo que nos obliga a hacer un par de cambios para que funcione correctamente el WebSVN. En primer lugar, como en las directivas del /etc/apache/apache2.conf sólo se cargan los sites habilitados mediante IncludeOptional sites-enabled/*.conf, se crea un enlace simbólico para que quede de la siguiente forma:
# ls -l /etc/apache2/sites-enabled/000-default.conf
Aparte, se modifica el contenido para que el Alias del WebSVN pueda funcionar bien, ya que por defecto se crea el fichero /etc/apache2/conf.d/websvn, el cual
no es procesado correctamente. Además se modifican los 'Order allow, deny' y 'Allow from all' por la nueva directiva 'Require all granted':
lrwxrwxrwx 1 root root 35 Jan 1 17:42 /etc/apache2/sites-enabled/000-default.conf -> ../sites-available/000-default.conf
# cat /etc/apache2/sites-enabled/000-default.conf
Se reinicia el Apache y ya se puede acceder al WebSVN:
<VirtualHost *:80> ServerAdmin webmaster@localhost DocumentRoot /d/webs/victorsanchez2.com ErrorLog ${APACHE_LOG_DIR}/error.log CustomLog ${APACHE_LOG_DIR}/access.log combined #Websvn Alias /websvn /usr/share/websvn <Directory /usr/share/websvn> ## No MultiViews DirectoryIndex index.php Options FollowSymLinks ## MultiViews #DirectoryIndex wsvn.php #Options FollowSymLinks MultiViews ## End MultiViews ###Order allow,deny ###Allow from all Require all granted <IfModule mod_php4.c> php_flag magic_quotes_gpc Off php_flag track_vars On </IfModule> </Directory> </VirtualHost>
# invoke-rc.d apache2 restart
http://localhost/websvn 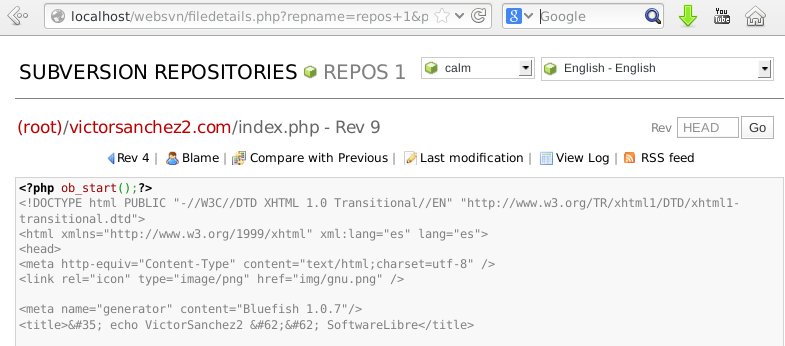
Liberado Football Ranking Generator v0.1
He estado haciendo algunas modificaciones en el código del generador de clasificaciones de fútbol para que generase automáticamente tanto las jornadas de la primera vuelta como de la segunda, que es lo que tenía pendiente.
Y por fin tengo la primera versión totalmente funcional. Aquí la tenéis, licenciada bajo GPLv3. Me hubiese gustado mucho poder documentarlo en más detalle, crear unos diagramas UML, etc., pero a día de hoy me resulta bastante difícil hacerlo tanto como me gustaría. Así que, mientras no pueda sacar algo más de tiempo, voy a indicaros brevemente los pasos a seguir para hacerlo funcionar y si tenéis cualquier duda, podéis preguntarme sin problemas.
Si alguien tiene sugerencias, dudas, o desea colaborar, al final de esta página tiene mis datos para lo que haga falta. Programa para generar clasificaciones de fútbol v2.0
Después de tenerlo parado un tiempo he vuelto al trabajo con ello y he migrado todo el código anterior (GTKmm, PostgreSQL y C++), para hacerlo
funcionar con Apache+PHP+MySQL.
La interfaz es la misma, podéis verla aquí: http://victorsanchez2.com/frg/muestra_clasificacion.php. Pero ahora ya está más preparado para crecer y añadirle nuevas funcionalidades. He pensado en añadir por ejemplo:
Cebrereña: Ascenso a Tercera División 2010
Monitorizando sistemas con Nagios 3.2.0 para GNU/Linux
Mi idea es mostrar cómo se monta un sistema de monitorización como Nagios, en este caso en una Debian Squeeze GNU/Linux. Comenzar es bastante sencillo, luego poco a poco iremos avanzando en la configuración.
Instalación:
$ su
Comprobar que se ha instalado correctamente accediendo por web a:
# apt-get update && apt-get install nagios3 # apt-get install nagios-plugins nagios-plugins-extra nagios-snmp-plugins (Instalación de los plugins, opcional) # apt-get install nagios3-doc (Documentación de Nagios)
http://localhost/nagios3 (Usuario=nagiosadmin, Contraseña=<contraseña elegida>)
Configuración:
# cd /etc/nagios3 (Editar los .cfg como se desee. Si no se quiere hacer nada especial, no es necesario este punto)
Instalación de NRPE (Nagios Remote Plugin Executor):
# apt-get install nagios-nrpe-plugin nagios-nrpe-server
Si se han hecho cambios en la configuración, será necesario hacer una recarga:
# /usr/lib/nagios/plugins/check_nrpe -H 127.0.0.1 (Comprobar la instalación y la versión)
# /etc/init.d/nagios3 reload
Con esto es suficiente para tener instalado Nagios. Por defecto monitorizará los siguientes servicios, accesibles a través del menú Service Detail de la interfaz web:
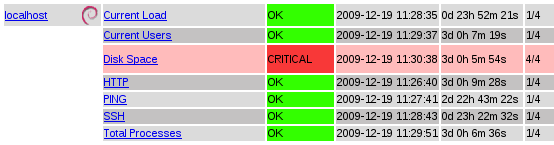
Antes de lanzarnos a monitorizar más máquinas, vamos a terminar esta primera parte comprendiendo la estructura de directorios y sus funcionalidades:
HOWTO: Xplanet GNU/Linux
Xplanet es un programa que nos permite tener como fondo de escritorio una imágen dinámica de nuestro planeta (entre
otras muchas cosas). A mi me encanta cómo queda, puedes tener en un golpe de vista todo el planeta, mostrando las zonas
nocturnas y diurnas mediante una proyección rectangular. A eso vamos a añadir también el estado de las nubes, muy apropiado
estos días para ver huracanes y tormentas.
Voy a intentar explicaros desde cero todos los pasos que hay que dar para tener por ejemplo este fondo de escritorio. Luego ya podréis personalizarlo como vosotros queráis, un rápido vistazo al man de xplanet os indicará su potencial: 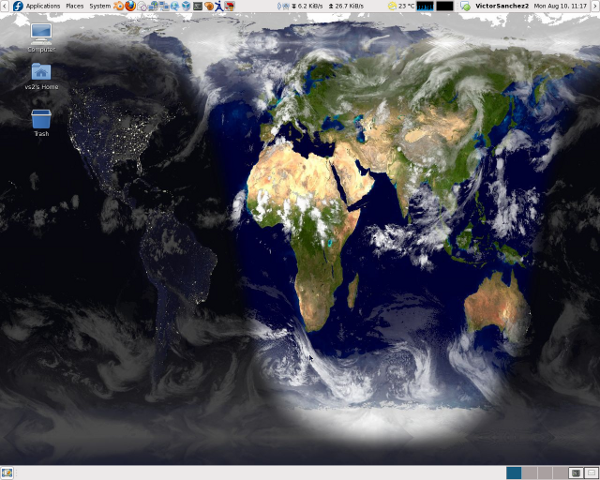
apt-get install xplanet xplanet-images (distribuciones basadas en Debian)
yum install xplanet (Distribuciones basadas en RedHat)
El siguiente paso es crearnos una carpeta con nuestras imágenes, por ejemplo /home/usuario/.xplanet/images y copiar ahí las imágenes de la tierra diurna y nocturna que se nos han creado con la instalación de los paquetes:
mkdir -p /home/usuario/.xplanet/images
Con la instalación de los paquetes se nos creará el fichero /usr/share/xplanet/config/default (en Debian es un enlace simbólico a /etc/xplanet/config/default mientras que en Fedora no). Hay que editarle y en la parte de [earth] poner nuestras rutas:
cp -p /usr/share/xplanet/images/earth.jpg /home/usuario/.xplanet/images cp -p /usr/share/xplanet/images/night.jpg /home/usuario/.xplanet/images
map=/home/usuario/.xplanet/images/earth.jpg
Para la imagen de las nubes vamos a utilizar un script que se ejecutará cada hora y la descargará de un servidor externo. Tendréis que modificar el $Filename para que apunte a la imagen de nubes:
night_map=/home/usuario/.xplanet/images/night.jpg cloud_map=/home/usuario/.xplanet/images/clouds.jpg (de este hablaremos a continuación)
#!/usr/bin/perl
# ------------------------------------------------------------------------------------
# Program for downloading XPlanet cloud images from a random mirror
#
# Copyright (c) 2003, cueSim Ltd. http://www.cueSim.com, Bedford, UK
#
# ------------------------------------------------------------------------------------
#
# Redistribution and use, with or without modification, are permitted provided
# that the following conditions are met:
#
# * Redistributions of source code must retain the above copyright notice,
# this list of conditions and the following disclaimer.
# * Neither the cueSim name nor the names of its contributors may
# be used to endorse or promote products derived from this software without
# specific prior written permission.
#
# THIS SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY
# EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES
# OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT
# SHALL THE COPYRIGHT OWNER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL,
# SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT
# OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
# HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,
# OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS
# SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
#
use LWP::Simple;
# Set options:
# - where to save the downloaded file (default is current directory)
my $Filename = "/home/usuario/.xplanet/images/clouds.jpg";
# - how often the image is updated on the server
my $MaxDownloadFrequencyHours = 2;
# - how many times to retry, if the server doesn't respond
my $MaxRetries = 3;
## Note: excessive requests to a single image server is discouraged.
## This script limits max retries, does not download more frequently
## than every two hours (the file is generated every 3 hours). and
## picks a random mirror location for every download.
##
## Change these settings at the risk of being blacklisted from the
## image servers.
# Get file details
if(-f $Filename)
{
my @Stats = stat($Filename);
my $FileAge = (time() - $Stats[9]);
my $FileSize = $Stats[7];
# Check if file is already up to date
if($FileAge < 60 * 60 * $MaxDownloadFrequencyHours && $FileSize > 200000)
{
print "File is already up to date\n";
exit(1);
}
}
# Try several times to download the file if necessary
for(1..$MaxRetries)
{
# Get a random website to hit for the file
my $MirrorURL = GetRandomMirror("mirrors.txt");
# Download the file
print "Using $MirrorURL\nDownloading...\n";
my $Response = getstore($MirrorURL, $Filename);
# If successfully downloaded, that's it, nothing more to do
if( IndicatesSuccess($Response))
{
print "Finished: file successfully downloaded to $Filename\n";
exit(0);
}
# Warning that we're retrying another random server
print "Download not available, trying another website\n\n";
}
# Warning that no servers could be contacted
print "ERROR: Tried to download the file $MaxRetries times, but no servers could provide the file\n";
exit(2);
# Return codes of 200 to 299 are "success" in HTTP-speak
sub IndicatesSuccess()
{
my $Response = shift();
if($Response =~ /2\d\d/)
{
return(1);
}
else
{
return(0);
}
}
# Returns the name of an internet resource which can provide the clouds image
sub GetRandomMirror()
{
# Populate a list of mirrors
my @Mirrors = (
"http://user.chol.com/~winxplanet/cloud_data/clouds_2048.jpg",
"http://home.megapass.co.kr/~gitto88/cloud_data/clouds_2048.jpg",
"http://php.nctu.edu.tw/~ijliao/clouds_2048.jpg",
"ftp://ftp.iastate.edu/pub/xplanet/clouds_2048.jpg");
# Return one at random
return $Mirrors[rand scalar(@Mirrors)];
}
Ahora ya tenemos nuestras imágenes y Xplanet ya las tiene configuradas para utilizarlas. Lo próximo es lanzar xplanet y cambiar el fondo de escritorio para seleccionar /home/usuario/.xplanet/images/xplanet.jpg, que será la imagen que se actualizará periodicamente. Xplanet permite muchos parámetros, voy a mostraros un par de ejemplos para que luego podáis trastear vosotros con ellos como más os guste. Ejecutar:
xplanet -geometry 1280x1024 -latitude 0 -longitude 0 -num_times 1 -output /home/usuario/.xplanet/images/xplanet.jpg
Os creará la imagen /home/usuario/.xplanet/images/xplanet.jpg, ahora podréis modificar el fondo de escritorio y seleccionar esa imagen, la cual irá actualizándose periódicamente y que ya no será necesario tocar en más ocasiones. Se puede hacer desde las utilidades que nos proporcione nuestro escritorio o mediante consola con:
gconftool-2 -t str -s /desktop/gnome/background/picture_filename /home/usuario/.xplanet/images/xplanet.jpg
Jugando con los parámetros podréis ajustarlo como más os guste, yo ahora mismo tengo puesta una proyección rectangular (echar un vistazo al man para ver todas las posibles proyecciones) de la siguiente forma, que es la imagen que he puesto al inicio de este HOWTO:
xplanet -geometry 1280x1024 -latitude 40.46 -longitude -4.46 -num_times 1 -output /home/vs2/.xplanet/images/xplanet.jpg -projection rectangular
Para hacer que se ejecute automáticamente xplanet al entrar en nuestro escritorio, en Gnome de puede hacer desde Sistema->Preferencias->Sesiones y añadir un programa de inicio por ejemplo con el contenido:
xplanet -geometry 1280x1024 -latitude 40.46 -longitude -4.46 -num_times 1 -output /home/vs2/.xplanet/images/xplanet.jpg -projection rectangularPara que luego se actualice periodicamente las zonas con la luz del día y la noche, lo que se puede hacer es crear un script que ejecute el comando que deseamos. En este caso lo voy a llamar /home/vs2/.xplanet/scripts/actualiza-fondo-xplanet:
xplanet -geometry 1280x1024 -latitude 40.46 -longitude -4.46 -num_times 1 -output /home/vs2/.xplanet/images/xplanet.jpg -projection rectangular
Después se añade una entrada en el cron, editando como root el fichero /etc/crontab para que se ejecute cada 5 minutos:
0-59/5 * * * * vs2 /home/vs2/.xplanet/scripts/actualiza-fondo-xplanet
Espero que os guste tanto como a mi :) Descargando RTMP (Real Time Messaging Protocol) con un script (para GNU/Linux)
Comienzo la historia desde el principio de cómo he llegado a la necesidad de tener que descargar vídeos por streaming RTMP.
Todo comenzó cuando me enteré que en rtve.es tenían colgados los capítulos de la serie que le gusta a mi madre, Amar en tiempos revueltos. No es una serie corta, ¡ni mucho menos!, son unos 200-250 capítulos por temporada, ¡y van por la cuarta!, así que me propuse bajarlos todos para que mi madre pudiese verlos tranquilamente en la televisión. Tenía todo lo necesario:
Primer problema, mi disco duro multimadia no lee archivos .flv, así que habrá que procesarlos para convertirlos en .avi por ejemplo. Luego contaré cómo hacerlo, vamos primero con el script. Me decidí por hacerlo en Perl. Están algunas cosas metidas a pelo, espero que me disculpéis, tiempo siempre se saca para una madre, pero no le sobra a uno.
#!/usr/bin/perl -w
El archivo restantes.dat es donde van metidas todas las direcciones de los capítulos que me faltan por descargar, no es más que el HTML que sale de guardar la página de la cuarta temporada, por ejemplo http://www.rtve.es/television/amar/videoscuarta/. Yo lo he cortado hasta donde empiezan los vídeos porque alguna vez he tenido algunas líneas que dan problemas con el split (todo sería currárselo un poco más, así que ya sabéis ;)), y tiene la forma que trae por defecto, pero eliminando todo el código HTML superior:
my $fich_indice="restantes.dat"; my $i=1; open(FICHERO_INDICE,"$fich_indice") || die "ERROR: No se pudo abrir el fichero $fich_indice\n"; chomp(@fich_indice=<FICHERO_INDICE>); @lineas=grep(/mediateca/,@fich_indice); #print @lineas; foreach $linea(@lineas){ print $linea; @capitulo=split(/"/,$linea); print $capitulo[1],"\n"; `wget $capitulo[1];`; @html=split(/\//,$capitulo[1]); print $html[$#html],"\n"; #Ultimo elemento del array $fich_descarga=$html[$#html]; open (FICHERO_DESCARGA,$fich_descarga) || die "ERROR: No se pudo abrir el fichero de descarga $fich_descarga\n"; chomp(@fich_descarga=<FICHERO_DESCARGA>); @linea_descarga=grep(/flv\"/,@fich_descarga); print @linea_descarga,"\n"; foreach $capitulo_flv(@linea_descarga){ print $capitulo_flv,"\n"; @flv=split(/"/,$capitulo_flv); print $flv[3],"\n"; `wget http://rtve.es$flv[3];`; $i++; print $i,"\n"; } close(FICHERO_DESCARGA); } close(FICHERO_INDICE);
<td><a href="http://www.rtve.es/mediateca/videos/20090506/amar-tiempos-revueltos-cap168/499742.shtml">Episodio 168</a></td>
En ese restantes.dat están todos los capítulos seguidos, de forma que luego pueda buscar las líneas donde aparece la palabra mediateca, que es la que yo he identificado como única para extraer en este caso el .shtml correspondiente (499742.shtml será el primero y a continuación todos los demás), que será ahí donde esté el .flv a descargar. Así que lo filtro con un grep y obtengo la dirección completa del flv, por ejemplo /resources/TE_SAMARE/flv/4/5/1241627647054.flv. Como veis le falta el http://rtve.es, así que se lo añado y utilizo wget para descargarlo. Así de sencillo. Ya tenemos un bucle que realiza lo siguiente:
<td class="r">50 min.</td> <td class="r">06/05/2009</td> </tr> <tr> ...
Un ejemplo sería el siguiente, en el cual vamos se convierte el vídeo 11.flv a 11.avi:
mencoder 11.flv -ofps 25 -ovc xvid -oac mp3lame -lameopts abr:br=128 -srate 48000 -vf scale -zoom -xy 720 -xvidencopts fixed_quant=4 -o 11.avi
Así podremos hacer un sencillo script que recorra todos los .flv que hemos bajado llamando a mencoder para procesar cada uno de los vídeos. ¡Os lo dejo como ejercicio!
Bueeeeeeno, ahí va la base para que lo adaptéis :), el mayor problema es eliminar el .flv para sustituirlo por el .avi, que es lo que hace ${i/.flv}.avi:
for i in *.flv; do echo $i ${i/.flv}.avi; done
Segundo problema. Hoy me he llevado la desagradable sorpresa al lanzar el script de que a partir del 173 de la temporada 4, lo han puesto para descarga por streaming mediante el protocolo RTMP. A día de hoy con wget no se puede bajar, así que me he puesto a investigar hasta que he encontrado un programa que me va a permitir adaptarlo a mi script para lanzarlo desde línea de comandos automatizando la tarea. Se trata de rtmpdump, que después de instalar el paquete:
apt-get install libssl-dev
y compilarlo:
$ make rtmpdump
Podemos descargar el .flv de la siguiente forma:
$ make streams
./rtmpdump_x86 -r "rtmp://videos1.rtve.es/ondemand/resources/TE_SAMARE/flv/1/5/1242233070151.flv" -o 173.flv
Así que mañana me pondré a adaptarlo en mi script para poder continuar descargando los vídeos de manera automatizada.
Editado: Leí el lunes que Adobe ha "pedido" que rtmpdump sea eliminado de Sourceforge: http://barrapunto.com/articles/09/06/08/0924255.shtml PS: Una televisión pública y los formatos privativos. ¡Manda huevos!. Y por si fuera poco, otro tema que se cuece estos días, todos los alumnos de 5º de primaria tendrán un portátil con licencias con Windows. Así nos luce el pelo, venga dinero que se marcha al extranjero en licencias de software privativo teniendo alternativas libres y que dejarían el dinero en España en contratos de implantación, mantenimiento y formación. Pero no, es mucho mejor hacer lo que van a hacer y luego dicen que la salida de la crisis será social o no será. Mientras siga habiendo gente que crea a nuestros políticos, tenemos lo que nos merecemos. Si algo tengo claro es que saldremos los últimos de esta crisis. En mi opinión, primero saldrá Estados Unidos, que subirá los tipos, luego lo hará Europa, que subirá los tipos y por último España con sus españoles que tendrán que remar el doble para remontar lo que se les viene encima. Qué panorama Dios mío, ¡qué panorama!. Jornadas de Software Libre de la UAM: 4-8 de mayo
Actualizado: Descarga las charlas y los scripts de Shell Scripting.
La semana del 4 al 8 de mayo se celebrarán en la Universidad Autónoma de Madrid de Madrid las Jornadas sobre Software Libre y GNU/Linux con las charlas que se indican a continuación. Esperamos vuestra asistencia y deseamos que os agraden:
Lunes 4:
16:00 - 16:30 => Presentación
16:30 - 17:00 => El compilador GCC, por Adrián González
17:10 - 17:55 => Valgrind, la ayuda del programador, por Roberto Naharro
18:00 - 18:45 => Depurando con GDB y DDD, por David Navarro
Martes 5:
14:30 - 14:30 => Escribiendo textos científicos con TeXMacs, por Pablo Angulo (en Ciencias)
16:00 - 16:45 => Shell Scripting Básico, por Víctor Sánchez
17:00 - 17:45 => Shell Scripting Avanzado, por Víctor Sánchez
18:00 - 18:45 => El lenguaje Ruby, por Sául Vargas
Miércoles 6:
16:00 - 16:45 => El entorno de programación Eclipse, por David Navarro
17:00 - 17:30 => Documentación con Doxygen, por Alejandro Serrano
17:40 - 18:30 => Control de versiones con Subversion, por Alejandro Serrano
Jueves 7:
16:00 - 17:00 => Matemáticas con SAGE, por Pablo Angulo (en Ciencias)
17:30 - 18:15 => Interfaces gráficas con Qt, por Saúl Vargas
18:15 - 19:00 => Pon en marcha tu servidor =>, por David Navarro y Alejandro Serrano
Viernes 8:
14:30 - 15:30 => SAGE: Avanzado, por Pablo Angulo (en Ciencias)
Nooooooooooo!!!!!!!!!!!!!!!!!!!!!!!!!!!!
En el artículo anterior os comenté que andaba últimamente con muchas ISOs, con mucho tráfico de datos. Es software de HP y apuntes, documentación, máquinas virtuales... Bueno, a lo que voy. Que resulta que hoy me disponía a instalar un software en una máquina virtual, así que enchufo mi disco duro externo y... zas!, no me lo automonta. Prueba para acá, prueba para allá, intentos de montarlo a mano por aquí y por allá, pero nada. Sudores fríos, blasfemias por aquí, blasfemias por allá. Abro el gparted y me dice que la tabla de particiones no tiene formato. ¡Cómo que mi disco de 1TB no tiene formato! Tengo varias copias de seguridad de los datos más importantes, pero seguro que perder un montón de DVDs de software de HP, Máquinas Virtuales personalizadas que ocupan una barbaridad y documentos y más documentos que he tenido que ir bajando uno a uno, no me iba a hacer ninguna gracia. Así que ya un poco resignado, echo un vistazo por Internet, alguna vez he tenido que recuperar algún dato y sé lo difícil que suele ser recuperar algo que se ha perdido. ¡Cuánto equivocado estaba! (en parte también porque no es lo mismo recuperar datos borrados que una tabla de particiones, pero ambas cosas pueden llegar a ser muy complejas). Os pongo los pasos a seguir para recuperar la tabla de particiones perdida en un par de minutos :)
# apt-get install testdisk
El funcionamiento es muy sencillo, sólo hay que seleccionar el disco duro (ya sea interno o externo) y pulsar en
analizar. Él se encarga de encontrar la tabla de particiones perdidas, después se le dice que lo grabe y ya está,
disco duro con muuuuuuchos gigas de información, recuperado. Decir también como apunte que era una partición ext3 y otra NTFS las que contenía el disco duro y que ha recuperado TestDisk.
# testdisk Si es que encima está licenciado bajo GPL (http://www.cgsecurity.org/wiki/TestDisk), vaya una joya. No te acostarás sin saber una cosa más :) ¿Extraer el contenido de una ISO sin grabar un CD/DVD?
Últimamente estoy teniendo que encontrarme con muchas ISOs, bastantes de menos de 100MB. Para mi es un gasto enorme e inútil tener que grabar un CD para eso. Había leído alguna vez que existía una forma de extraer los datos directamente a nuestro disco duro. Y la verdad es que la solución ha sido muy simple. La comparto con vosotros, seguro que a más de uno le es de utilidad este ejemplo para sistemas UNIX.
# mount ejemplo.iso /media/cdrom -t iso9660 -o loop
Y en /media/cdrom ya tenemos todo nuestro contenido extraído. I love this game :)
Encantado de volver a verle señor LISP (2)
Una vez que dimos el primer paso de aplicar el efecto de redondear las esquinas a una única foto, yendo paso por paso, vamos a automatizarlo para utilizarlo en tantas imágenes como deseemos con una simple llamada a una función. La creamos para ver un ejemplo: (define (round-corners in-filename out-filename) (let* ( (image (car (gimp-file-load RUN-NONINTERACTIVE in-filename in-filename))) (drawable (car (gimp-image-get-active-layer image))) ) (script-fu-round-corners image drawable 15 TRUE 8 8 15 TRUE FALSE) (gimp-file-save RUN-NONINTERACTIVE image drawable out-filename out-filename) (gimp-image-delete image)))
(round-corners "/tmp/img/foto.xcf" "/tmp/img/foto2.xcf")
Una vez creada la función, ya tenemos los conocimientos para continuar con el siguiente paso de la automatización, crear un bucle.
Pero una cosa antes de continuar, ¿sólo va a funcionar con imágenes .xcf? ¡Pues entonces creo que no va a ser de mucha utilidad en la mayoría de las ocaciones!. ¡Todo tiene solución! O mejor dicho, siempre existe una forma de hacerlo en este mundo del Software Libre, voy a explicar como llevarlo a cabo con imágenes .jpg, ya que hay que aplanar las capas antes de guardarlo. Lo incluyo junto con la generación del bucle, con lo cual ya tendremos un ejemplo totalmente funcional con el que podremos aplicar el efecto de redondear las esquinas a varias (o muchísimas imágenes) de una forma rápida, muy rápida. Ya lo veréis con cifras ;) ; ; Ejemplos: ; (round-corners-victorsanchez2 "/home/vsanchez/img/*.jpg") ; (round-corners-victorsanchez2 "/home/vsanchez/img/*.xcf") ; (round-corners-victorsanchez2 "/home/vsanchez/img/fotolibre*.jpg") ; ; Origen: http://lists.xcf.berkeley.edu/lists/gimp-user/2006-November/009015.html ; ; Modificaciones: VictorSanchez2 ; - Error en los parámetros de unbreakupstr ; (define (round-corners-victorsanchez2 pattern) (let* ( (filelist (cadr (file-glob pattern 1))) (xcfname) (jpgname) (filename) (image) (drawable) ) (while filelist (set! filename (car filelist)) (print (list "Procesando:" filename)) (set! image (car (gimp-file-load RUN-NONINTERACTIVE filename filename))) (set! xcfname (unbreakupstr (butlast (strbreakup filename ".")) ".")) (set! xcfname (string-append xcfname ".xcf")) (set! drawable (car (gimp-image-get-active-layer image))) (script-fu-round-corners image drawable 15 TRUE 8 8 15 TRUE FALSE) (gimp-file-save RUN-NONINTERACTIVE image drawable xcfname xcfname) (set! image (car (gimp-file-load RUN-NONINTERACTIVE xcfname xcfname))) (set! jpgname (unbreakupstr (butlast (strbreakup xcfname ".")) ".")) (set! jpgname (string-append jpgname "-new")) (set! jpgname (string-append jpgname ".jpg")) (set! drawable (car (gimp-image-flatten image))) (gimp-file-save RUN-NONINTERACTIVE image drawable jpgname jpgname) (gimp-image-delete image) (set! filelist (cdr filelist)) (print (list "...finalizado:" filename)) ) ) )
(script-fu-round-corners image drawable 15 TRUE 8 8 15 TRUE FALSE)
Y se pueden encontrar pulsando en Examinar en la consola Script-Fu y escribiendo el nombre de la función. Así podremos modificarlos a nuestro gusto. Son los mismos que se nos muestra cuando se hace a mano.
 Hasta aquí llega la explicación de hoy. Ya tenemos algo 100% funcional, pero en la siguente página del manual que haga, explicaré como eliminar un efecto para mi bastante molesto que se produce en la generación intermedia. Eliminar la capa blanca del fondo y dejarlo transparente. Antes había prometido mostrar con números el tiempo que se tarda en aplicar el efecto a mano o mediante Script-Fu. Voy con una gráfica donde se verá bastante rápido. El número de imágenes a tratar representado en el eje X y el tiempo empleado en el Y. Empiezo a contar el tiempo desde que abrimos GIMP en ambos casos, contando todos y cada uno de los pasos que hay que dar. Para una sola imagen el tiemplo empleado a mano o con Script-Fu es practicamente el mismo, 30 segundos, a partir de ahí, la cosa ya cambia: 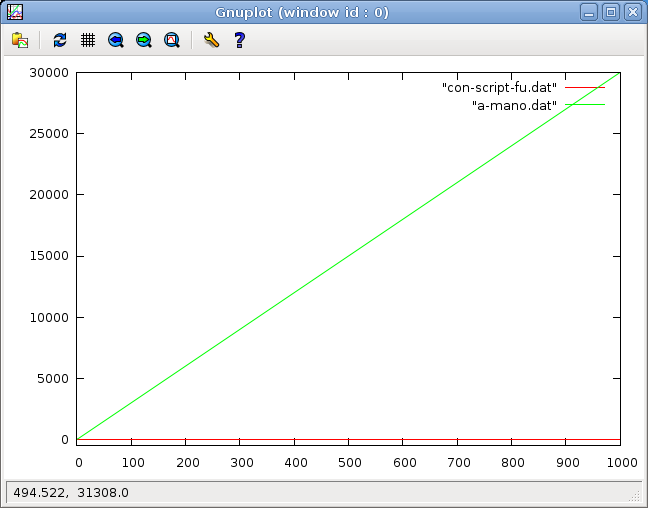
El tiempo con Script-Fu es constante, ¡30 segundos!, da igual aplicarlo a 1 o 1000 imágenes, el bucle que hemos hecho se encargará de ello por nosotros. ¡Viva GIMP! :) Como apunte final por hoy, a modo de recuerdo, sólo indicar los comandos utilizados para generar la gráfica con Gnuplot:
gnuplot> set yrange [-500:30000]
gnuplot> plot "con-script-fu.dat" w lines gnuplot> replot "a-mano.dat" w lines Más sobre automatizar & imágenes
Pues hoy, tratando con más imágenes, me he visto en la obligación de renombrar más de medio centenar de imágenes, y como siempre, hacerlo a mano... pufffff. Así que me he hecho un script en un par de minutos para automatizarlo. Lo comparto con todos vosotros, seguro que a más de uno le es de utilidad, si no hoy, tal vez mañana.
#!/bin/bash
if [ $# -ne 1 ]
then
echo "Uso: $0 <extension_origen> <extension_destino>"
echo "Ejemplos: "
echo "$0 jpg jpg"
echo "$0 JPG jpg"
exit 1
fi
j=0
for i in `ls *.$1`
do
j=$((j+1))
if [ $j -lt 10 ]
then
mv $i puertas_abiertas08_0$j.$2
else
mv $i puertas_abiertas08_$j.$2
fi
echo "Procesado $j"
done
Por favor, si alguien tiene dudas con cualquier script, no dude en escribirme a victorsanchez2 en gmail.com o añadir mi cuenta de Jabber victorsanchez2 en jabberes.org. Encantado de volver a verle señor LISP
La de vueltas que da la vida. Durante la carrera tuve que utilizar LISP, y aunque teníamos a Eduardo Pérez, que para mi es un gran profesor, no me gustaba demasiado este lenguaje de programación, por no decir que nada. Probablemente la asignatura de Ingeniería del Conocimiento fuese una de las más duras de la carrera y más difíciles de aprobar. Pensé que no volvería a tocar LISP ni nada que se le pareciese en mi vida, pero fíjate por dónde, en estos días ando utilizándolo y con mucho gusto. No es exactamente LISP como tal, sino Scheme, y tampoco es 100% Scheme, sino un derivado que utiliza GIMP. Así que animado por todo ello, voy a intentar hacer una guía para aquellas personas que se quieran iniciar en este apasionante mundo de los Script-Fu de GIMP. Para empezar algunas páginas de referencia:
Todo empezó porque quería aplicar el efecto de redondear esquinas a muchas fotos a la vez (Filtros->Decorativos->Esquinas redondeadas). Hacerlo una a una puede ser un trabajo muy costoso, así que decidí invertir unas horas en aprender a automatizar este tipo de tareas. 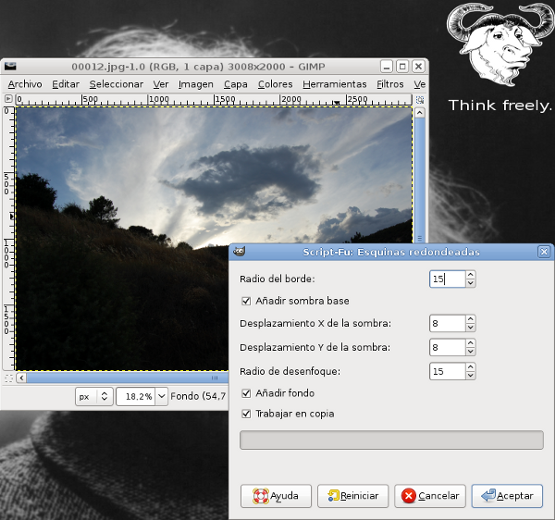 Lo primero que conseguí fue aplicar el efecto a una única imagen, paso por paso. Abrimos la consola de Script-Fu de GIMP. Dependiendo de la versión de GIMP se encontrará en Filtros->Script-Fu->Consola o Exts->Script-Fu->Consola por ejemplo. 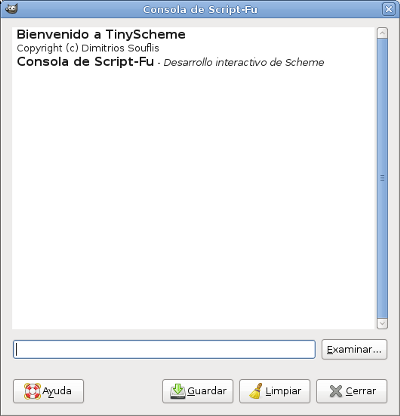 Escribimos en la consola lo siguiente para cargar la imagen en modo no-interactivo:
(gimp-file-load RUN-NONINTERACTIVE "/home/vsanchez/img/00012.xcf" "/home/vsanchez/img/00012.xcf")
Si todo ha ido bien, nos devolverá una lista con un número, el cual utilizaremos luego.
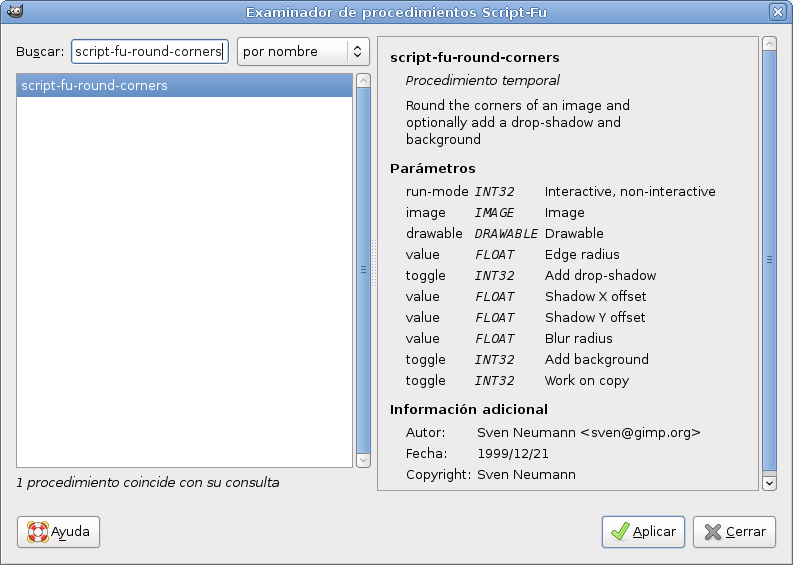
Durante el desarrollo, será importante saber qué es lo que devuelve cada función y qué parámetros recibe. Para ello podemos pulsar en Examinar en la consola Script-Fu y buscar la función que deseamos: 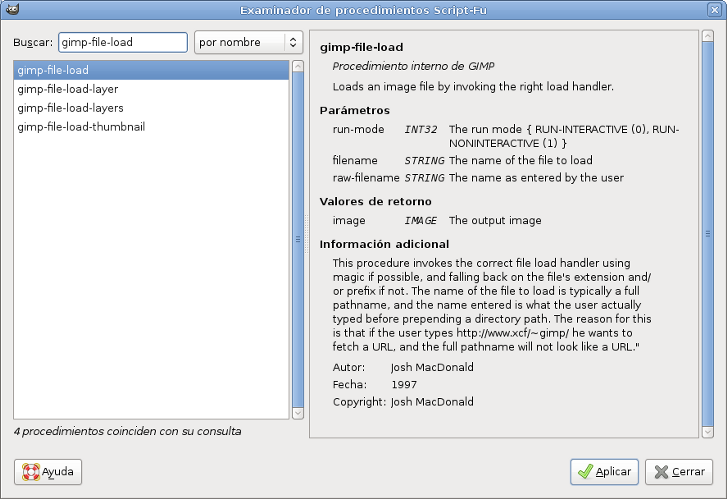
(gimp-image-get-active-layer 20)
Ahora ya podemos aplicar nuestro efecto de redondear esquinas. Utilizando la función script-fu-round-corners, con 20 y 53 como parámetros primero y segundo, ya que son los identificadores que nos han devuelto para la imagen y la capa. En cada caso pueden cambiar, no son más que valores que identifican una imagen, capa, etc. Los demás parámetros son los valores que queremos darle para que el se aplica a nuestra imagen el redondeado de esquinas. He puesto los mismos que por defecto se aplican cuando aplicamos a mano el efecto desde GIMP. Se pueden ver también al pulsar en Examinar en la consola como hemos comentado antes.
(script-fu-round-corners 20 53 15 TRUE 8 8 15 TRUE FALSE)
Para finalizar, guardar la imagen, volviendo a pasar el 20 y 53 como parámetros de la función gimp-file-save:
(gimp-file-save RUN-NONINTERACTIVE 20 53 "/home/vsanchez/img/00012_2.xcf" "/home/vsanchez/img/00012.xcf")
Una captura de pantalla de cómo queda en la consola todo el proceso:
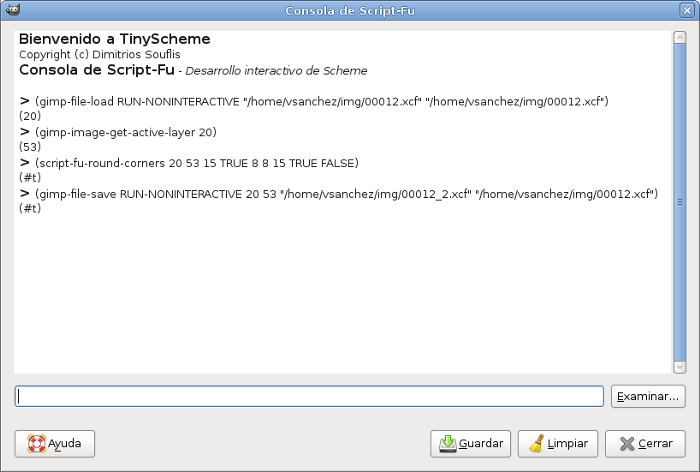 Bueno, no ponerse nerviosos, hay que gastar unas pocas horas en aprender para luego automatizar las tareas y tardar segundos en lo que antes nos llevaría horas. Paciencia :) Seguiré con la guía, poniendo más ejemplos. Lo siguiente es crear todo esto con una función sin tener que ir metiendo los parámetros a mano y a continuación crear un bucle para aplicar el mismo tratamiento a 1 o 50.000 fotos. Ahh, se me olvidaba, también hacerlo para un .jpg y otra cosa más, eliminar la capa blanca del fondo para que las imágenes queden transparentes. Pruebas en el dominio
En este mes de diciembre voy a hacer pruebas para incluir nuevas funcionalidades en la web. Se agradece toda colaboración y paciencia :)  Programa para generar clasificaciones de fútbol: Ubuntu
Para los que uséis Ubuntu hay un cambio en el nombre del paquete de las librerías para PostgreSQL a tener en cuenta.
Mientras que en Debian los paquetes libpq-dev y postgresql-dev incorporan todas las librerías que necesitamos, en Ubuntu las de la parte de servidor y las de cliente, tienen los nombres libpq-dev y postgresql-server-dev-8.3, así que los paquetes a instalar en Ubuntu serían:
# apt-get install g++ postgresql libgtkmm-2.4-dev build-essential pkg-config libpq-dev postgresql-server-dev-8.3
Estoy haciendo algunas mejoras en el código y corriendo bugs, en breve subiré una nueva versión del programa y la explicación
de cómo probarlo.
Programa para generar clasificaciones de fútbol (y ahora también será generador de estadísticas)
En estos días estoy añadiendo algunas funcionalidades extras al programa, entre ellas
la de ir incluyendo todos los datos relativos a una base de datos (PostgreSQL) para posteriormente
poder calcular estadísticas de una forma sencilla y rápida y mantener un histórico de
todo lo que ha ido ocurriendo en la categoría.
Voy a liberar el programa aunque estoy haciendo muchísimos cambios y hay código de pruebas en bastantes módulos, así que no os tiréis al cuello ;-). Todo aquel que quiera colaborar en su desarrollo será bienvenido (mis datos están al final de la página). Yo no dispongo de todo el tiempo libre que me gustaría, pero aún así está bastante avanzado, funciona perfectamente y poco a poco voy añadiendo nuevas características y corrigiendo errores. Aquí tenéis el código liberado bajo la licencia GPLv3:  Generador de clasificaciones de
fútbol Generador de clasificaciones de
fútbol
Los pasos que deberían seguirse para alguien que quiera probarlo serían los siguientes: Ya que el programa está hecho con C++, gtkmm y PostgreSQL será necesario instalar el compilador para C++ y las librerías de desarrollo correspondientes. Además, si no se tiene instalado, también el paquete build-essential.
# apt-get install g++ postgresql libgtkmm-2.4-dev build-essential libpq-dev postgresql-dev pkg-config
La librería libpq (PostgreSQL library) tendrá que ser linkada en el Makefile, así
que en el apartado LIBS, deberá aparecer siempre al menos LIBS = -lpq. Si se me ha pasado por
alto alguna librería que no sea común en todas las distribuciones y SSOO, por favor, decídmelo.
Para poder crear la base de datos, añadir las tablas y usar phpPgAdmin por ejemplo, hay que disponer de un usuario de base de datos y configurar el fichero /etc/postgresql/8.3/main/pg_hba.conf para otorgar los permisos necesarios. Se comentan todas las líneas que aparecen y se dejan por ejemplo sólo las siguentes líneas (si necesitas más seguridad o acceso desde otras máquinas en el propio fichero viene bastante bien documentado):
host all all 127.0.0.1 255.255.255.255 trust sameuser
Una vez hecho esto, hay que reiniciar PostgreSQL con un:
local all all trust sameuser
/etc/init.d/postgresql-8.3 restart
La versión que yo tengo ahora mismo de PostgreSQL es la 8.3, si fuese otra sólo habría
que localizar donde estuviese el fichero pg_hba.conf
# apt-get install mlocate (si no está ya instalado)
Ahora vamos a crear un usuario de base de datos por ejemplo así:
# updatedb # locate pg_hba.conf
# su - postgres
Si queréis crear el mismo usuario que el que se use para el sistema resultará más sencillo para
los permisos de acceso, el manejo de los scripts, etc., no entro en temas de seguridad por ahora, eso ya lo dejo en manos de cada uno de vosotros.
$ createuser prueba ¿Será el nuevo rol un superusuario? (s/n) n ¿Debe permitírsele al rol la creación de bases de datos? (s/n) s ¿Debe permitírsele al rol la creación de otros roles? (s/n) n Una vez que ya está todo instalado los pasos a seguir serán los de configurar el proyecto, compilarlo y ejecutarlo. Cuando haga el manual lo pondré todo detallado. Por cierto, necesito un nombre para el programa, ya veré cuál le pongo :). También haré un manual detallado de cómo utilizarlo. ¡Necesito días de 30 horas! ^_^ Fotografía Reflex digital: Nikon D40 bajo Debian, Ubuntu...
 Existen problemas al conectar esta cámara a sistemas libres, en mi caso particular, con Debian. Era necesario aplicar un parche al núcleo (a partir de kernels Linux posteriores al 2.6.23 comentan que este problema se solucionó, pero por lo que he visto, no para todo el mundo). Existe otra forma de hacerlo que resulta bastante sencilla, sólo hay que cambiar la forma en que se comunican el sistema operativo y la cámara a través del USB. Para hacerlo, en el menú de la cámara hay que seleccionar lo siguiente:
Menú -> Configuracion -> USB -> MTP/PTP (en lugar de Mass Storage)
Si no se tiene instalado el programa gThumb, podemos hacerlo mediante un simple:
apt-get install gthumb
Cuando ya se tiene instalado gthumb y cambiado el modo a MTP/PTP,
se procede a encender y conectar la cámara mediante el USB al ordenador y gThumb ya se encargará de preguntar si
queremos importar las fotos, le decimos que sí y ya podemos obtener nuestras maravillosas fotos.
 Liberando un sencillo programa para generar clasificaciones de fútbol bajo GPLv3
Desde donde llego a recordar he estado jugando al fútbol. A esta gran afición se une otra de mis pasiones, la informática. A ambas, se une otra más, el Software Libre. Hace un par de años me hice un programilla en C para generar autoáticamente clasificaciones de fútbol, el último verano lo pasé a C++ y lo hice gráfico (gtkmm) para que les fuese más fácil de utilizar a unos amigos y ahora estoy haciendo algunos pequeños retoques. El programa lo que hace es generar una clasificación igual que ésta: Clasificación Me faltan muchísimas cosas por hacer. Me gustaría poder parametrizar aún más, mejorar los controles de errores..., pero por falta de tiempo no lo he podido hacer. Aún así, el programa hace perfectamente su cometido y en un minuto puedes tener generada tu clasificación y subida a tu servidor de FTP. Ya se encarga él solito de hacerlo todo, tú sólo tienes que meter los resultados ;). Para personalizarlo es necesario tener conocimientos de C++, pero todo aquel que lo quiera y no sepa cómo hacerlo, sólo tiene que decírmelo y yo se lo personalizo en un minuto. En estos días subiré el código para que lo utilice todo aquel que lo desee y si está interesado, también para colaborar. Aquí tenéis un pantallazo del programa: 
AWK al rescate
El potente AWK, no podía ser otro :) Estuve a punto de encontrarme en la misma situación que la vez anterior, escribir código con mis sentencias for, if, ... en lugar de aprovechar la maravilla de herramientas que tenemos a nuestra disposición, pero esta vez no ha sido así ñe ñe ñe. Tenía un archivo con varios miles de líneas, cada una de las cuales contenía la clave primaria de la tabla perteneciente a una base de datos. El problema: Contar el número de ocurrencias de cada clave primaria en el fichero. Lo primero que se me vino a la cabeza, un contador que cada vez que encontrase una ocurrencia, se incrementase para esa clave concreta. El problema en sí es algo más o menos fácil de resolver, pero existen varios problemas, es necesario hacerlo rápida y eficientemente. Un número excesivo de comparaciones, accesos a disco o el consumo elevado de memoria podría penalizar bastante, así que no podía hacerse a la ligera. Tenía una pequeña idea de que AWK podría servirme, pero mis conocimientos no eran demasiado profundos como para resolverlo por mi mismo, así que me puse a buscar por Internet, un poco por aquí, otro poco por allá, hasta que di con ello. Además me llevé una muy grata sorpresa ya que encontré la solución en la página de uno de los profesores más brillantes que he tenido a lo largo de mi carrera, Kostadin Korutchev. Aquí os muestro el código adaptado para el problema particular que tenía entre manos, contar el número de veces que aparece una cadena en un fichero:
#!/bin/sh
cat $1 \
| awk '{for(i=1;i<=NF;i++) print $i;}' \
| awk '{n[$1]++;}END{for(i in n) print n[i], i;}' | sort -nr
Y problema solucionado :) Destacar también que el script funciona si aparece más de una clave primaria por línea gracias al primer bucle. Una vez terminado el problema, podría haber parado aquí, pero yo no soy así, por lo tanto me he hecho el script a mano para comparar y ver el tiempo que me he ahorrado al aprender un poquito más de AWK (tal vez ahora no, pero para el futuro seguro que sí :) ) Decir que el fichero con las claves primarias estaba ordenado, y por lo tanto todas las ocurrencias de una misma clave estaban agrupadas. De no haber sido así, este segundo script no habría servido y la lógica hubiese tenido que ser mucho más compleja. Resaltar que el primer script funciona tanto para ficheros ordenados como desordenados. Después veremos unas pruebas donde os sorprenderéis de la velocidad a la que lo procesa. Me interesaban sólo aquellas claves primarias que apareciesen 1 o 2 veces, las demás se descartan, así que un script más o menos así me hubiese servido: #!/bin/sh o1=0 o2=0 sel_o=1 c=0 for i in `cat colas_obsoletas.dat` do # Almacena la clave actual y diferencia la clave seleccionada if [ $sel_o -eq 1 ] then o1=$i sel_o=2 else o2=$i sel_o=1 fi # Si las claves son distintas quiere decir que se han terminado de # contar las ocurrencias. # Si además el contador es 1 o 2, se muestra esa clave. if [ $o1 -ne $o2 ] && [ $c -eq 1 -o $c -eq 2 ] then if [ $sel_o -eq 1 ] then echo $o1 else echo $o2 fi fi # Si la clave anterior es distinta de la clave actual, inicializar el contador # sino, aumentar el contador porque se está contando la siguiente ocurrencia # de la clave primaria if [ $o1 -ne $o2 ] then c=1 else c=`expr $c + 1` fi done Está claro que AWK es mucho más potente y fácil de utilizar. Ahora voy a hacer una prueba para ver cuánto tardaría el script AWK en darme la salida que necesito. Para empezar me genero un archivo con 4000 líneas y un número aleatorio entre 1 y 100 en cada una de ellas, después lanzo mi script y redirijo la salida a un fichero: Pruebas de velocidad: $ for i in `seq 1 2000`; do echo -e "`expr $RANDOM % 100`\n`expr $RANDOM % 100`" >> fichero.out; done $ time ./colas_awk.sh fichero.out > fichero_awk.out real 0m0.022s user 0m0.024s sys 0m0.008s Con 8000 líneas tarda más o menos lo mismo. Si tengo un rato me hago una gráfica de cómo crece el tiempo en función de las líneas del fichero y así aprovecho para mostraros lo útil que es el programa gnuplot. Algo que he aprendido también, es que junto al programa gawk (GNU awk) se instala pgawk (Profiling gawk), que nos permite ver las trazas de por dónde ha ido pasando nuestro script. Si ahora lo ejecutamos con pgawk:
#!/bin/sh
cat $1 \
| pgawk '{for(i=1;i<=NF;i++) print $i;}' \
| pgawk '{n[$1]++;}END{for(i in n) print n[i], i;}' | sort -nr
el resultado será el mismo, pero además genera el fichero awkprof.out, en el cuál podemos ver lo qué ha ido ocurriendo en la ejecución:
# perfil de gawk, creado Sun Mar 2 14:25:34 2008
# Regla(s)
4000 {
4000 n[$1]++
}
# bloque(s) END
END {
100 for (i in n) {
100 print n[i], i
}
}
Me he comprado seis libros en Amazon, así que espero seguir aprendiendo y poder escribir a menudo. Ojalá os guste. Shell Scripting (entre otras cosas)
Últimamente estoy teniendo la suerte de tocar muchas máquinas UNIX, sobre todo Solaris, pero también HP-UX y AIX. Antes solía hacerme mis scripts para automatizar algunas tareas del día a día y para las prácticas de la facultad, ahora, por fortuna, tengo que usarlo para trabajar. No tengo pensado hacer un manual sobre Shell Scripting ya que por la Red podemos encontrar muchos y muy buenos, por ejemplo http://tldp.org/LDP/abs.html/, lo que pretendo es dar una visión general (o muy detallada) sobre sistemas UNIX, sus diferencias, virtudes, defectos... iré hablando de Shell Scripting, sistemas, monitorización, seguridad... sin restricciones. Normalmente escribiré artículos pequeñitos o experiencias que me hayan llamado la atención. Cuanto más voy aprendiendo, más cuenta me doy de lo poco que sé, pero también de la gran potencia que me brindan todos estos conocimientos. Como primer apunte me gustaría hablar de una situación con la que me encontré hace poco desarrollando un script para una Korn Shell encargado de procesar una serie de situaciones en una base de datos, que se ejecuta automáticamente cada noche y lo almacena con el nombre Envio + la fecha de ejecucion. El mayor problema fue el de saber cómo borrar todos aquellos envíos que tuviesen más de un mes de antigüedad. Si por ejemplo hoy nos encontramos a 24 de febrero, debería borrarse el envío relativo al 24 de enero. Lo interesante viene cuando hay que borrar por ejemplo desde el 1 de marzo, ya que se deben limpiar, además del 1 de febrero, también los del 29 y 30 de enero que no se borraron en febrero. Otro caso extra, si febrero es bisiesto, sólo debe borrarse el 30 de enero porque desde el 29 de febrero ya se habrá hecho. Lo veréis más claro si os lo muestro aquí. Al final terminé implementando tres clases diferentes de borrados, dependiendo de si me encontraba en alguno de los bloques:
if [ $strdia -eq 01 -a $strmes -eq 03 ]
en total 102 líneas de código contando comentarios.
then #Si es dia 1 y el mes 3 (marzo), borrar los dias 29, 30 y 31 de enero que no se borran en febrero #En el caso de que febrero sea bisiesto, borrar solo el 30 y 31 #Si es bisiesto if [ $stranio%4 -eq -0 ] && [ $stranio%100 -ne 0 -o $stranio%400 -eq 0 ] then ... else ... fi elif [ $strdia -eq 01 ] && [ $strmes -eq 5 -o $strmes -eq 7 -o $strmes -eq 10 -o $strmes -eq 12 ] then #Si es dia 1 y es el mes siguiente a alguno de los que tienen 30 dias #(abril, junio, septiembre y noviembre), borrar el dia 31 de hace dos meses ... else #Borrar todos los de hace un mes ... fi Yo sabía que debía existir una forma más sencilla de hacerlo, pero busqué y no logré encontrar nada que me hiciese poder alejarme de la idea de dividir el código con esa estructura para borrar cada envío correspondiente en función del día y mes en que me encontrase. Más tarde estuve con otro script que todas las noches se encarga de obtener información mediante consultas a una base de datos y lo envía a un Datawarehouse. Una noche en mi casa leyendo sobre Shell Scripting me topé con lo siguiente y me llevé las manos a la cabeza:
find . -mtime +30 -exec rm -fr {} \;
El comando find utilizado de esta forma se encarga de borrar aquellos archivos o directorios que fueron modificados hace más de 30 días en el directorio actual.
¡¡¡¡Diosssss!!!! ¡¡¡¡Sabía que existía!!!! Me dio muchísima rabia encontrarlo, pero también una enorme
satisfacción. Una línea en lugar de 102... ainssss.
Así que lo único que tuve que hacer fue adaptarlo para mi caso particular y ahora podré usarlo siempre que quiera. Leyendo el man, he visto que con -atime (access time) se puede utilizar la última vez que se ha accedido al archivo y con -ctime (create time) la fecha de creación.
find . -ctime +30 -name 'Envio*' -exec rm -rf {} \;
El conocimiento nos hará libres. Unos leves consejillos sobre seguridad.
¿Qué es lo primero que hay que tener en cuenta cuando se abre un puerto en nuestro ordenador y se ofrece un servicio? Fácil, la seguridad. Hoy he estado montando un servidor SSH y otro FTP (Debian GNU/Linux Sid en este caso) para poder acceder a mi ordenador desde cualquier parte y para compartir algunas cosillas con un amigo. Muchos días intentan acceder a mi ordenador (seguro que al tuyo también, si sois un poco curiosos podéis echar un vistazo al fichero /var/log/auth.log y ahí tendréis registrado quién ha querido acceder a vuestro ordenador, cúantas veces lo ha hecho y ¡si lo ha conseguido!. En este caso la conexión por SSH será para mi, y no me hace ni pizca de gracia que alguien pueda colarse por ahí a mi ordenador, así que tomo ciertas precauciones básicas y otras no tanto: 1. Suelo cambiar regularmente de contraseña. 2. Utilizo contraseñas fuertes, sobre todo para root. 3. Me mantengo al día de las actualizaciones de seguridad. 4. Hago algunos retoques en el firewall y los archivos de configuración según voy aprendiendo cosas nuevas. Algo muy sencillo y que mucha gente permite que se haga es el acceso por SSH como root. Si fueses un malo malísimo, ¿cuál sería el primer usuario con el que probarías para entrar? Exactamente, con el usuario root. Dependiendo de las distribuciones, el acceso por SSH como root viene habilitado:
PermitRootLogin yes
Lo que debemos hacer es dirigirnos al fichero /etc/ssh/sshd_config, modificar ese yes
por un no y reiniciar el servidor con /etc/init.d/ssh restart.
Si alguna vez queremos entrar como root a nuestro ordenador,
es mejor entrar como un usuario normal y luego desde dentro cambiar de usuario a root.
Un par de utilidades muy buenas y que nos mostrarán un resumen del estado de la seguridad de nuestro sistema son los programas chkrootkit y rkhunter. Instaladlos y probadlos, tal vez más de uno se lleve una sorpresa. El otro punto que hoy quería tener controlado es el de la privacidad. No quiero que el amigo al que voy a dar acceso al FTP pueda cotillearme documentos privados o simplemente borrar algo sin querer. Lo que he hecho ha sido instalarme vsftpd - The Very Secure FTP Daemon y elegir en el fichero de configuración /etc/vsftpd.conf alguna de las características que buscaba:
1. anonymous_enable=NO (No quiero que nadie se conecte sin autenticarse)
He tocado más elementos de la configuración, pero estos eran los principales que quería tener.
2. write_enable=NO (Los usuarios no podrán escribir) 3. user_config_dir=/etc/vsftpd/users (directorio con los ficheros de configuración de cada usuario) 4. chroot_local_user=YES (lo más importante en este caso para mi, el usuario no podrá subir en el árbol de directorios por encima del que se le ha asignado como raíz) Instalar y configurar un servidor, ya sea SSH o FTP, está ampliamente documentado, así que si estáis interesados en hacerlo sólo tendréis que mirar en cualquier buscador y aprender. Con la llegada al mundo UNIX, y más concretamente al mal llamado Linux, de usuarios noveles y con poca preparación, tal vez estemos pecando de "buenas personas", de intentar hacer la vida más fácil a esos usuarios que acaban de llegar para captar a más y más. Yo estoy en parte de acuerdo con esa política porque ese impulso vendría muy bien al mundo del Software Libre, pero mucho cuidado con los pasos que se dan. Pongo como ejemplo la intención de incluir drivers propietarios en Ubuntu, un acto deleznable y que espero no se produzca jamás. Solaris, *BSD, Debian, Ubuntu, Suse, Red Hat... estamos asistiendo a una lucha por hacerse con un mayor trozo del pastel, cada uno a su manera, pero todos sabiendo muy bien el más que posible futuro que nos espera. El fichaje de Ian Murdock o el impulso de OpenSolaris por parte de Sun es una clara muestra. El elemento más lento decidirá el rendimiento del sistema. (Léase alumnos)

Los torpes no llegarán a nada, se sabe, aunque nos duela. Cuando hablo con los alumnos o sus padres, cuando me cuentan las ganas que tienen de estudiar para poder ejercer esa profesión que tanto les gusta... me da pena ver y pensar que no están recibiendo la formación adecuada porque todos deben ir al mismo ritmo en clase. Y al decir esto, lo que se hace es que todos deben ir al ritmo de los más lentos o de los que no tienen mayor interés por estudiar. A los que de verdad quieren estudiar, cuando lleguen a la universidad les exigirán unos conocimientos que en la mayoría de los casos no han recibido en la medida que debiesen. Están poniendo trabas a su futuro por hacer que los que van más lentos puedan aprobar el curso. Cuando el otro día vi a nuestra queridísima Ministra de Educación, Mercedes Cabrera, decir que los alumnos de Bachillerato podrán pasar de curso con cuatro suspensos me dieron ganas de meter la mano por el televisor y darle un cogotazo. ¿Para qué esta medida? ¿Para que haya menos “fracaso escolar” y poder mostrar unas mejores cifras? ¿Para que no abandonen tantos alumnos los institutos y haya menos paro?. Señora ministra, el nivel no debe bajarse, ¡DEBE SUBIRSE!. Los alumnos del presente serán los que en un futuro muy cercano tiren de España hacia delante (o tal vez hacia atrás). Se está obligando a que los más listos se adapten al ritmo de los más torpes. Aunque suene egoísta, aunque nos duela, existen distintos niveles y la educación debe ir orientada a que todos progresen y se preparen para sus objetivos. En el caso de que no puedan hacerse varios carriles de circulación, deben ser los torpes y los gamberros los que se pongan detrás. ¿Cuáles son los pasos normales de cada tipo de alumno?
Dentro de cada grupo puede haber casos muy distintos y también pasar en ocasiones de uno a otro. Dependiendo de las compañías o la educación familiar, se pueden dar unos vuelcos tremendos. Soy estudiante y debido a mi trabajo seguro que lo seguiré siendo toda mi vida. Sé muy bien de lo que estoy hablando, en una proporción muy alta de colegios e institutos ocurre. Hasta la universidad, el ritmo de clase se adapta a los torpes, mientras que los problemáticos molestan a los demás, y los listos y normales se aburren en clase y no aprenden más allá de lo básico. ¿Es ese el país que queremos? ¿Esa es la educación que nos enseñan? Una cosa es ser todos iguales en cuanto a derechos y otra muy distinta ésta. La naturaleza es cruel, los que no son capaces de sobrevivir, caen. Aquí en España no, muchos no pueden correr para que otros puedan andar. Los que hayáis leído todo pensaréis que soy un egoísta, o que todos deben tener los mismos derechos. Sí, todos deben tener los mismos, pero la libertad de uno termina cuando influye en la de los otros. |
